
Einführung
Sie suchen nach einem Text-to-Speech-Tool. Vielleicht für Ihre geschäftlichen Telefonnachrichten. Vielleicht, um zu verstehen, wie Sie unter den vielen Lösungen auf dem Markt die richtige auswählen können. Vielleicht, weil Sie von KI-Stimmen gehört haben und beurteilen möchten, ob sie tatsächlich im beruflichen Kontext einsetzbar sind.
Dieser Leitfaden beantwortet all diese Fragen. Wir decken ab, was TTS wirklich ist, wie es funktioniert, in welchen Kontexten es angewendet wird und vor allem, warum Tools für den Massenmarkt nicht dieselben Anforderungen erfüllen wie solche, die für die weit verbreitete, aber erstaunlich wenig dokumentierte Verwendung in der Unternehmenstelefonie entwickelt wurden.
Wenn Ihr Bedarf sofort besteht, können Sie Ihre erste professionelle Sprachnachricht kostenlos auf Voconix erstellen in weniger als 30 Sekunden, mit 25 Stimmen und über 10 000 Musikstücken. Wenn Sie das Thema lieber erst einmal gründlich verstehen möchten, ist die Fortsetzung für Sie.
1. Definition und Geschichte: Wie TTS vom Labor in die Unsichtbarkeit gelangte
Die Definition
Text-to-Speech (TTS) oder Sprachsynthese ist die Technologie, die geschriebenen Text in hörbare Sprache umwandelt. Aus einem Eingabetext erzeugt sie eine Audiodatei, die man auf jedem Gerät abspielen, in eine Anwendung integrieren, auf eine Website streamen oder in eine Telefonanlage laden kann.
Dies ist das Gegenteil von Spracherkennung (Speech-to-Text), die den umgekehrten Weg von Sprache zu Text geht.
Das Ergebnis ist eine Audiodatei (MP3, WAV, OGG, je nach Verwendungszweck). Die Frage lautet nicht mehr «Funktioniert das?», sondern «Ist die Qualität für meinen Zweck ausreichend?». Und die Antwort lautet seit einigen Jahren in fast allen professionellen Fällen "Ja".
Sechzig Jahre Entwicklung in vier großen Etappen
Die Sprachsynthese wurde nicht erst mit der KI geboren. Ihre Geschichte reicht bis in die Mitte des 20. Jahrhunderts zurück und ist ein hervorragendes Beispiel dafür, wie sich eine Technologie von einer Laborspielerei zu einer unsichtbaren Infrastruktur des Alltags entwickelt.
1950er bis 1970er Jahre: Physikalische Synthesizer. Die ersten TTS-Systeme waren elektronische Maschinen, die versuchten, die physikalischen Mechanismen der menschlichen Stimme nachzuahmen: Vibrationen der Stimmbänder, Resonanzen der Mundhöhle, Artikulationen. Das Ergebnis war sofort als künstlich erkennbar. Eine flache, leblose Roboterstimme, die eher an Science-Fiction als an echte Kommunikation erinnerte.
1980er bis 2000er Jahre: Synthese durch Verkettung. Ein grundlegend anderer Ansatz setzt sich durch: Anstatt die Stimme zu simulieren, wird ein Mensch aufgenommen, der Tausende von Silben und einzelnen Wörtern spricht und diese dann zu einem beliebigen Satz zusammensetzt. Die Qualität macht einen großen Sprung. Diese Technologie versorgt die ersten sprechenden GPS-Geräte und automatischen Messenger. Aber die Verbindungen zwischen den Lauten sind manchmal immer noch spürbar, und die Intonation ist oft mechanisch.
Jahre 2000-2015: Statistische Modellierung. Ansätze wie HMM (Hidden Markov Models) ermöglichen es, die menschliche Stimme statistisch zu modellieren und eine flüssigere Synthese zu erzeugen. Die Stimme klingt bei kurzen Sätzen natürlicher, bleibt aber bei langen oder komplexen Texten erkennbar.
Seit 2016: die neuronale Revolution. WaveNet, das 2016 von Google DeepMind entwickelt wurde, stellt einen klaren Bruch dar. Dieses tiefe neuronale Netz lernt direkt aus menschlichen Aufnahmen, um Schallwellen Probe für Probe zu erzeugen. Zum ersten Mal führen synthetische Stimmen menschliche Zuhörer in Blindtests regelmäßig in die Irre. Nachfolgemodelle (Tacotron, FastSpeech, VALL-E) setzen diesen Weg fort, bis hin zu den Stimmen von heute, die einen Text mit glaubwürdigen emotionalen Nuancen erzählen können.
Dieses Qualitätsniveau bieten heute professionelle TTS-Tools wie Voconix: natürlich klingende neuronale Stimmen, ohne den mechanischen Aspekt früherer Generationen.

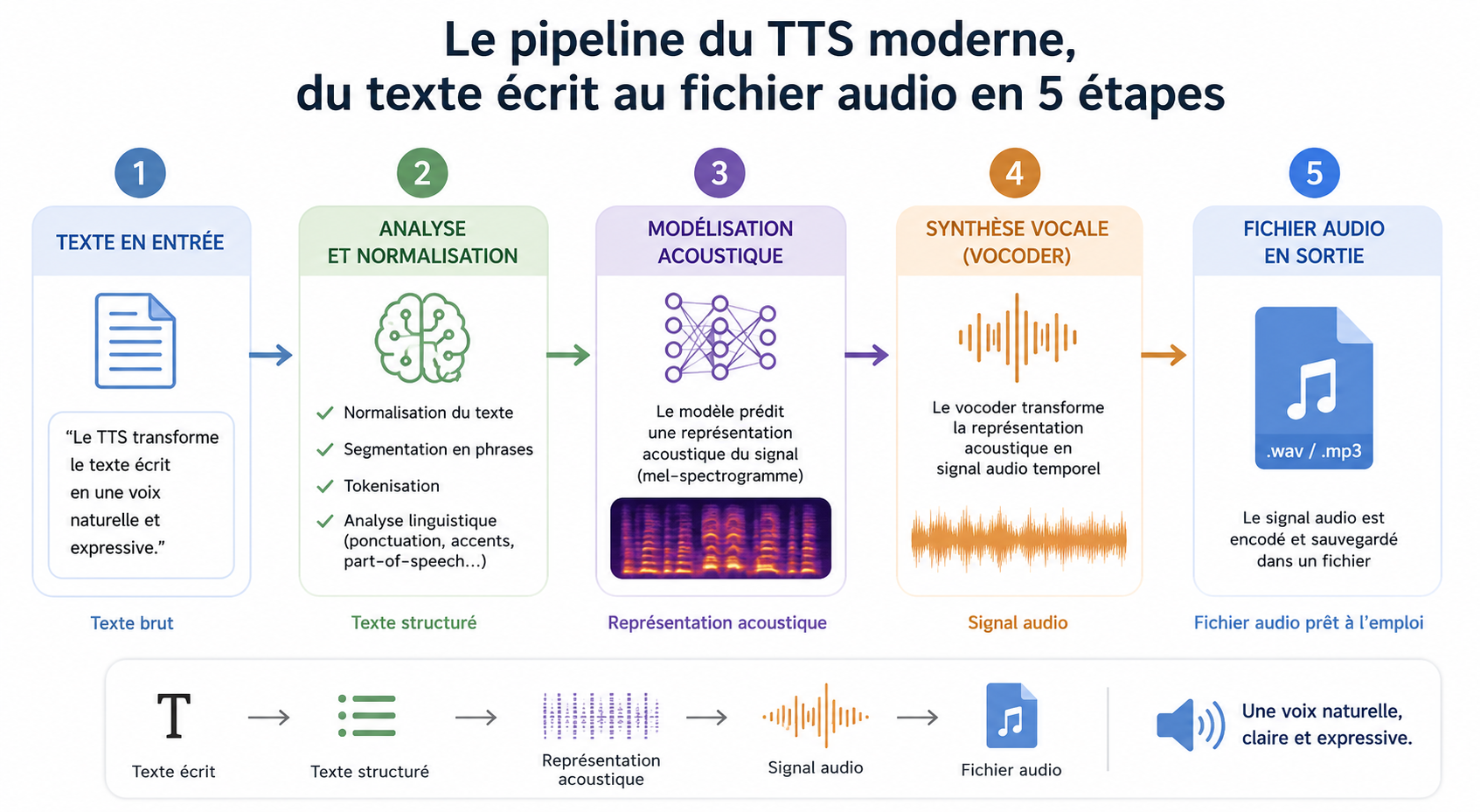
2. Wie funktioniert modernes TTS? Technologie einfach erklärt
Zu verstehen, wie TTS funktioniert, erklärt, warum manche Werkzeuge besser sind als andere und warum manche Nutzungskontexte anspruchsvoller sind als andere.
Schritt 1: Die Analyse des Textes, erst verstehen, dann sprechen
In der ersten Phase des TTS wird kein Ton erzeugt. Sie besteht aus den Text verstehen, Das ist viel komplexer, als es auf den ersten Blick scheint.
Ein Mensch, der laut liest, löst automatisch Hunderte von Mehrdeutigkeiten auf, ohne sich dessen bewusst zu sein. Ein TTS-System muss diese explizit auflösen.
Homographen. Das Wort «Sohn» wird unterschiedlich ausgesprochen, je nachdem, ob es sich auf Kinder oder Angelschnur bezieht. Die richtige Aussprache hängt vom Kontext ab, den das System analysieren können muss.
Ziffern und Zahlen. «15. März» wird als «fünfzehn März» gelesen. «1 500 €» muss «eintausendfünfhundert Euro» lauten. «05 57 22 92 10» muss Ziffer für Ziffer gelesen werden. Jedes digitale Format hat seine eigenen Leseregeln, und ein Fehler in einer Unternehmensnachricht fällt sofort auf.
Abkürzungen und Akronyme. «SNCF» wird Buchstabe für Buchstabe ausgesprochen. «NASA» wird als Wort ausgesprochen. Ein gutes TTS-System unterscheidet diese Fälle durch komplexe Regeln und Datenbanken mit Sonderfällen.
Interpunktion und Prosodie. Ein Komma bedeutet eine leichte Pause und einen besonderen Tonfall. Ein Fragezeichen verändert die melodische Kontur des Satzes. Die Interpunktion ist eine Partitur, die der menschliche Leser intuitiv liest, und die TTS muss lernen, sie zu interpretieren.
Die besten TTS-Systeme verwenden Modelle zur Verarbeitung natürlicher Sprache (NLP), um diese Mehrdeutigkeiten aufzulösen, bevor sie auch nur einen Ton erzeugen. Voconix integriert zusätzlich eine Einprägen schwieriger Aussprachen : Sie korrigieren einmal die Aussprache eines Eigennamens oder eines untypischen Begriffs, und sie wird für alle Ihre Nachrichten dauerhaft beibehalten.
Schritt 2: Die phonemische Sequenz, die Sprache in elementare Laute zerlegen
Nachdem der Text analysiert wurde, wandelt ihn das System in eine Sequenz von Phoneme, Die Phoneme sind die elementaren Klangeinheiten der Sprache. Im Französischen gibt es etwa 36 verschiedene Phoneme. «Bonjour» zerfällt in /b/, /ɔ̃/, /ʒ/, /uʁ/.
Diese Transkription ist mit prosodischen Informationen angereichert: Wo setzt man Akzente, wie moduliert man die Dauer der einzelnen Laute, welche Tonhöhenvariationen nimmt man an, damit der Satz natürlich klingt.
Schritt 3: Spracherzeugung, von Phonemen zu Schallwellen
Ein neuronales Modell, das mit Hunderttausenden von Stunden menschlicher Sprachaufnahmen trainiert wurde, nimmt die Phonemsequenz als Input und erzeugt die akustischen Merkmale der Stimme. Eine Komponente namens «Vocoder» wandelt diese Merkmale in eine hörbare Schallwelle um.
Das Ganze läuft in einigen zehn Millisekunden ab. Die resultierende Audiodatei ist einsatzbereit.
Was gute TTS von schlechten unterscheidet
Die Größe und Vielfalt der Trainingsdaten Ein Modell, das mit 100.000 Stunden vielfältiger menschlicher Sprache gefüttert wurde, ist von Natur aus besser als ein Modell, das mit 1.000 Stunden einer einzigen Stimme trainiert wurde.
Die Verwaltung des Langzeitkontextes : Die besten Modelle passen ihre Intonation an die Bedeutung des gesamten Satzes an, nicht Wort für Wort.
Die natürliche Prosodie : Die Kunst, Pausen, Akzente und Rhythmusvariationen an den richtigen Stellen zu setzen. Dies ist das Kriterium, das vom Ohr am unmittelbarsten wahrgenommen wird.
Die Robustheit bei schwierigen Fällen : Eigennamen, Fachbegriffe, gemischte Sprachen. Ein guter TTS bewältigt diese Fälle ohne Abstriche.
3. Die wichtigsten Anwendungsfälle von Text-to-Speech
TTS wird in sehr unterschiedlichen Kontexten angewendet, wobei jeder Verwendungszweck spezifische Einschränkungen mit sich bringt. Diese Unterschiede zu verstehen ist entscheidend für die Wahl des richtigen Werkzeugs.
Zugänglichkeit: die ursprüngliche Berufung
Bevor er ein Produktivitätswerkzeug war, war und ist der TTS ein grundlegendes Hilfsmittel für die Barrierefreiheit. Für Menschen mit Sehbehinderungen, Legastheniker oder Menschen mit kognitiven Störungen, die das Lesen beeinträchtigen, ist er ein Tor zur Welt der Schrift. Ein Screenreader, der eine Webseite vokalisiert, eine Anwendung, die eingehende Nachrichten vorliest: Das sind Anwendungen, bei denen der TTS eine Rolle als Hebel für die tatsächliche Inklusion spielt.
Die Erstellung von Audio- und Videoinhalten
Content-Ersteller (YouTuber, Podcaster, Online-Trainer, Marketingteams) nutzen TTS, um Videos zu erzählen, ohne ihre Stimme aufzunehmen, oder um Inhalte in mehreren Sprachen schnell zu lokalisieren. Dieser Markt ist mit der steigenden Qualität von KI-Stimmen explosionsartig gewachsen.
E-Learning und Berufsbildung
E-Learning integriert TTS massiv, um Erzählungen von Modulen zu generieren, ohne für jede Aktualisierung des Inhalts einen Schauspieler einstellen zu müssen. In diesem Zusammenhang ist die Konsistenz über die Zeit hinweg entscheidend: Ein Kurs mit 50 Modulen muss einheitlich klingen, auch wenn die Module über mehrere Monate hinweg produziert werden.
Sprachassistenten und Konversationsagenten
Siri, Google Assistant, Alexa: Sie alle verwenden TTS, um laut zu antworten. Sprachgesteuerte KI-Agenten für Callcenter verwenden TTS-Systeme mit sehr niedriger Latenz für Gespräche in Echtzeit.
Embedded und IoT
GPS, Bahnhofsansagen, interaktive Terminals, industrielle Warnsysteme: TTS, das in physische Geräte eingebettet ist, erfüllt radikal andere Anforderungen als die Nutzung in der Cloud (geringes Gewicht des Modells, Offline-Betrieb, Robustheit in verrauschter Umgebung).
Geschäftstelefonie: die am weitesten verbreitete Nutzung in Unternehmen
Es ist die am weitesten verbreitete Nutzung in der Unternehmenswelt und paradoxerweise eine der am wenigsten dokumentierten. Hunderttausende von französischen Unternehmen verwenden TTS täglich für ihre professionelle Sprachnachrichten, Die meisten Menschen sind sich dessen bewusst, ohne es zu wissen oder es so zu formulieren.
Jedes Mal, wenn ein Anrufer einen Begrüßungsnachricht, ein IVR-Menü, Eine Stimme, die ihm eine Wartezeit ankündigt, oder ein professioneller Anrufbeantworter, ist die Wahrscheinlichkeit groß, dass es sich um eine synthetische Stimme handelt. Diese Verwendung ist so üblich, dass sie durchschaubar geworden ist.
Diese Nutzung verdient eine eigene Entwicklung, da sie sich technisch und operativ so stark von anderen Anwendungsfällen unterscheidet. Genau das ist der Kern dessen, was Voconix anbietet.
4. TTS in der Geschäftstelefonie: Warum es eine Welt für sich ist
Was allgemeine Tools nicht bewältigen
Wenn man eine Stimme aus dem Off für ein Video generiert, spielt das Audioformat keine Rolle: Ein Standard-MP3 funktioniert überall. Die professionelle Telefonie ist eine Welt mit ihren eigenen technischen Regeln, rechtlichen Einschränkungen und betrieblichen Logiken.
Das Audioformat ist die erste unsichtbare Einschränkung.
Professionelle Telefonsysteme (IPBX wie 3CX oder Mitel, traditionelle PABX oder Cloud-Lösungen wie Aircall oder Ringover) akzeptieren nicht jede beliebige Audiodatei. Jedes System hat seine eigenen Spezifikationen :
| Art des Systems | Erwartetes Format | Frequenz | Verschlüsselung |
|---|---|---|---|
| Klassisches PSTN / PABX | WAV mono | 8.000 Hz | µ-law oder A-law |
| Moderne VoIP-Telefonanlage | WAV mono | 8.000 oder 16.000 Hz | 16-Bit-PCM |
| Cloud-Lösungen | Variable | Oft flexibler | MP3 oder WAV je nach Plattform |
Eine WAV-Datei, die mit 44.100 Hz (Standard-CD-Qualität) erzeugt wurde und in eine Telefonanlage importiert wird, die für 8.000 Hz konfiguriert ist, wird entweder abgelehnt oder mit einer verzerrten Stimme wiedergegeben. Ihr Telekom-Installateur muss die Datei dann manuell umwandeln, was Verzögerungen mit sich bringt.
Eine präzise Aussprache ist eine funktionale Anforderung.
In einer Telefonansage ist es das erste Wort, das der Anrufer hört, und oft ist es der Name des Unternehmens. Eine ungefähre Aussprache erzeugt schon in den ersten Sekunden einen Eindruck von Nachlässigkeit. Telefonnummern, Öffnungszeiten, Eigennamen: alles Fälle, in denen ein nicht spezialisierter TTS enttäuschen kann.
Eine Telefonnachricht ist nie eine nackte Stimme.
Sie wird mit einer Hintergrundmusik gemischt. Diese Mischung aus Sprache und Musik unterliegt genauen Regeln (die Musik muss 12 bis 18 dB unter dem Sprachpegel liegen), und die verwendete Musik muss in Frankreich frei von Rechten für professionelle Telefonie sein (SACEM- und SCPA-Vorschriften).
Ein Unternehmen verwaltet eine Flotte von Nachrichten, nicht eine einzelne Datei.
Sie verfügt im Durchschnitt über etwa zehn Nachrichten : Begrüßungsnachricht, Anrufbeantworter, IVR-Menüs, Wartenachricht, Voicemailboxen Diese Botschaften müssen untereinander kohärent sein (gleiche Stimme, gleiche Musikwelt, gleiche Lautstärke) und regelmäßig aktualisiert werden.
Die Lieferung an den Installateur ist der letzte Kilometer, der oft vergessen wird.
Die Einrichtung einer neuen Nachricht läuft in der Regel über den Telekom-Installateur. Ohne automatische Benachrichtigung kann dieser Vorgang Stunden oder Tage dauern, was problematisch ist, wenn eine dringende Schließung noch am selben Abend angekündigt werden muss.
Voconix wurde entwickelt, um all diese Einschränkungen in einem einzigen Tool zu erfüllen.
An Ihre IPBX angepasstes Audioformat, gespeicherte Aussprache,
Katalog mit 10.000 lizenzfreien Musikstücken,
Verwaltung Ihrer gesamten Nachrichtenflotte, und
automatische Lieferung an Ihren Telekom-Installateur.
5. KI-Stimme vs. menschliche Stimme: Welche soll ich für meine Nachrichten wählen?
Dies ist eine der häufigsten Fragen, sobald es um professionelle TTS geht. Die Antwort: Es kommt auf die Botschaft an.
Was die KI-Stimme besser kann
Schnelligkeit. Eine geänderte Nachricht (ein Zeitplan, ein Datum, ein neuer Mitarbeiter) wird innerhalb von 30 Sekunden ohne Aufnahmesitzung generiert.
Zeitliche Konsistenz. Eine KI-Stimme ist heute und in drei Jahren identisch verfügbar, ohne Abweichungen in Klangfarbe oder Qualität.
Das Volumen. Wenn ein Unternehmen 40 Mitarbeiter mit jeweils einem Sprachbox zu erstellen, oder wenn ein Franchise-Netzwerk die gleiche Botschaft in 150 Betrieben mit lokalen Anpassungen einsetzen muss, ist KI-Sprache die einzige wirtschaftlich und betrieblich tragfähige Lösung.
Mehrsprachigkeit. Mit Voconix können Sie Nachrichten in Französisch, Englisch, Spanisch, Deutsch und Italienisch mit muttersprachliche Stimmen für jede Sprache, In einem einzigen Werkzeug.
Kosten. Die Kosten für eine qualitativ hochwertige TTS-generierte Sprachnachricht betragen nur einen Bruchteil der Kosten für eine Studioaufnahme mit einem professionellen Schauspieler.
Was die menschliche Stimme besser kann
Das komplexe emotionale Register. Bei einer wichtigen institutionellen Botschaft sorgt ein talentierter Schauspieler für eine emotionale Dimension, die die besten TTS noch unvollkommen wiedergeben.
Absolute Einzigartigkeit. Eine echte menschliche Stimme mit ihren leichten Unvollkommenheiten und ihrer Einzigartigkeit kann zu einem echten Signature Sound werden, der wiedererkennbar und einprägsam ist.
Kreative Interpretation. Ein Schauspieler interpretiert ein Briefing. Der TTS, auch wenn er noch so gut ist, hält sich an Regeln: Er spielt nicht.
Der richtige Ansatz: Je nach Botschaft beides kombinieren
Pour l’immense majorité des messages téléphoniques d’entreprise (accueil standard, IVR-Menüs, boîtes vocales des collaborateurs), la voix IA de qualité est non seulement suffisante, elle est préférable pour ses avantages opérationnels. Pour certains messages à haute valeur symbolique, la voix humaine garde sa place.
Voconix bietet beide Optionen: 25 verfügbare Stimmen, KI und menschlich, damit Sie je nach Botschaft, gewünschtem Register und Budget auswählen können.
Hören Sie sich unsere Stimmen zu Ihren eigenen Texten an, bevor Sie sich festlegen.
25 Stimmen in 5 Sprachen, kostenlos zum Ausprobieren verfügbar. Keine Kreditkarte erforderlich.
Kostenlos testen
6. Wie wählt man das TTS-Tool für die geschäftliche Telefonie aus?
Wenn Sie Ihre geschäftlichen Telefonansagen erstellen oder aktualisieren müssen, sollten Sie sich folgende Fragen stellen, bevor Sie sich entscheiden.
Ist das Ausgabeformat mit Ihrer Telefonanlage kompatibel? Fragen Sie Ihren Installateur nach dem genauen Format, das er in Ihre IPBX importieren kann (Samplingfrequenz, Kodierung, Mono oder Stereo). Eine Formatinkompatibilität führt entweder zu einer Ablehnung oder zu einem schlechteren Klang. Voconix generiert automatisch die richtigen Formate für jeden Systemtyp.
Bietet das Tool qualitativ hochwertige Stimmen in nativem Französisch? Testen Sie mit Ihren eigenen Texten, insbesondere mit solchen, die Eigennamen, Zahlen und branchenspezifische Geschäftsformulierungen enthalten.
Ist die Musik integriert und rechtlich nutzbar? Eine professionelle Telefonnachricht ohne Musik verliert an wahrgenommener Qualität. Überprüfen Sie, ob die angebotene Musik frei von Lizenzgebühren für die Verwendung in der professionellen Telefonie in Frankreich ist. Voconix umfasst über 10.000 lizenzfreie Musikstücke mit automatischer Sprach- und Musikmischung.
Verwaltet das Tool eine Flotte von Nachrichten über einen längeren Zeitraum? Nachrichtenverlauf, Organisation nach Mitarbeitern oder Standorten, Stimmkonsistenz über mehrere Jahre: Dies sind wesentliche Funktionen für ein Unternehmen, die in den meisten allgemeinen Tools nicht vorhanden sind.
Ist die Lieferung an den Installateur automatisiert? Ohne automatische Benachrichtigung bedeutet jede Aktualisierung eine manuelle Übertragung der Datei. Voconix benachrichtigt Ihren Installateur automatisch, sobald eine neue Nachricht bereitsteht.
Voconix erfüllt alle diese Kriterien.
Erstellen, verwalten und verbreiten Sie Ihre professionellen Sprachnachrichten selbstständig.
Entdecken Sie unsere Preise · Testen Sie kostenlos
7. TTS und ethische Fragen, die man kennen sollte
Ein umfassender Leitfaden zu TTS kann die ethischen Fragen, die diese Technologie aufwirft, nicht außer Acht lassen.
Sprachklonen: leistungsstark und im Rahmen
Die besten TTS-Technologien ermöglichen es heute, aus wenigen Minuten Aufnahmematerial einen Stimmklon einer Person zu erstellen. Legitim eingesetzt (z. B. damit eine Person mit einer degenerativen Krankheit ihre Stimme bewahrt), ist dies ein bemerkenswerter Fortschritt.
Ohne Zustimmung verwendet, ist dies eine schwere Verletzung der Persönlichkeitsrechte. Seriöse Plattformen schreiben strenge Mechanismen vor: Die betroffene Person muss ausdrücklich zustimmen, und Erkennungssysteme identifizieren nicht autorisierte Klone.
Für Unternehmen: Wenn Sie eine «Markenstimme» erstellen, die auf einer echten menschlichen Stimme basiert, stellen Sie sicher, dass die Person eine ausdrückliche Vereinbarung unterzeichnet hat, die die kommerzielle Nutzung und die gewünschte Nutzungsdauer abdeckt.
Audio-Deepfakes: eine reale Bedrohung
Bei der heutigen Qualität von KI-Stimmen ist es technisch möglich, sehr realistische Audioaufnahmen einer Person zu erstellen, die etwas sagt, was sie nie gesagt hat. Dies ist eine wachsende Bedrohung für das Vertrauen in Sprachauthentifizierungssysteme und den Ruf öffentlicher Personen. Die Antwort liegt in der Entwicklung von Erkennungstechnologien, in der Regulierung und in erhöhter Wachsamkeit.
Die Auswirkungen auf die Sprachberufe
Der Markt für professionelle Sprecher ist direkt von der steigenden Qualität des TTS betroffen. Die Branche passt sich an, mit Debatten über Rechte an Stimmbildern und Klonverträgen, aber die Transformation ist real.
8. Die Zukunft von TTS: Wohin geht die Technologie?
Nahezu keine Latenz. Die derzeit besten Systeme erzeugen Sprache mit einer Latenz von 75 bis 300 ms. Die Forschung zielt darauf ab, unter 50 ms zu fallen, damit KI-Sprachagenten in einem Gespräch nicht mehr von einem Menschen unterschieden werden können.
Kontrollierbare emotionale Expressivität. Die neuesten Modelle ermöglichen es bereits, Emotionen direkt in den Text zu injizieren. Diese Granularität wird noch verfeinert werden, bis eine vollständige Schauspielerführung möglich ist, ohne auch nur eine Sekunde Ton aufzuzeichnen.
Sprachpersonalisierung als Markenaktivposten. Unternehmen werden ihre Stimme genauso behandeln wie ihr Logo: ein Aktivposten, den es aufzubauen, zu schützen und auf alle Kontaktpunkte, einschließlich des Telefons, auszudehnen gilt.
Die Integration in konversationelle KI-Agenten. TTS wird ein Grundbaustein für Sprachagenten werden, die natürliches Sprachverständnis, Konversationsgedächtnis und Sprachwiedergabe in einem kontinuierlichen, natürlichen Fluss vereinen.
Transparente mehrsprachige Verwaltung. Mit den nächsten Modellen wird es möglich sein, in derselben Nachricht, mit derselben Stimme und ohne Qualitätsverlust zwischen verschiedenen Sprachen zu wechseln. Was heute noch eine technische Übung ist, wird zu einer grundlegenden Funktionalität werden.
Schlussfolgerung
Text-to-Speech hat in sechzig Jahren einen schwindelerregenden Weg zurückgelegt, von den ersten elektronischen Synthesizern bis zu den heutigen neuralen Stimmen, die das menschliche Ohr täuschen. Für Unternehmen stellt sich heute nicht mehr die Frage «Ist TTS gut genug?». Die Antwort lautet in der überwiegenden Mehrheit der beruflichen Fälle "Ja".
Die eigentliche Frage ist «Welches Werkzeug, für welchen Zweck, mit welchen Garantien?» Für die Geschäftstelefonie bedeutet dies eine Lösung, die die technischen Einschränkungen von Nebenstellenanlagen versteht, Sprache und Musik in einen einzigen Workflow integriert, die Konsistenz Ihrer Nachrichten über einen längeren Zeitraum hinweg verwaltet und die Lieferung an Ihren Installateur automatisiert.
Voconix ist diese Lösung.
Erstellen Sie Ihre professionellen Sprachnachrichten in 30 Sekunden, mit 25 Stimmen, über 10.000 lizenzfreien Musikstücken, in 5 Sprachen, mit automatischer Lieferung an Ihren Installateur.
Testen Sie kostenlos · Zu den Angeboten und Preisen
9. So erstellen Sie Ihre Text-to-Speech-Sprachmitteilung mit Voconix
Text-to-Speech ist eine Technologie, aber sie zu benutzen muss es nicht sein. Hier sehen Sie, wie Voconix einen reinen Text in eine professionelle Sprachnachricht umwandelt, die bereit ist, auf Ihrer Telefonzentrale abgelegt zu werden.
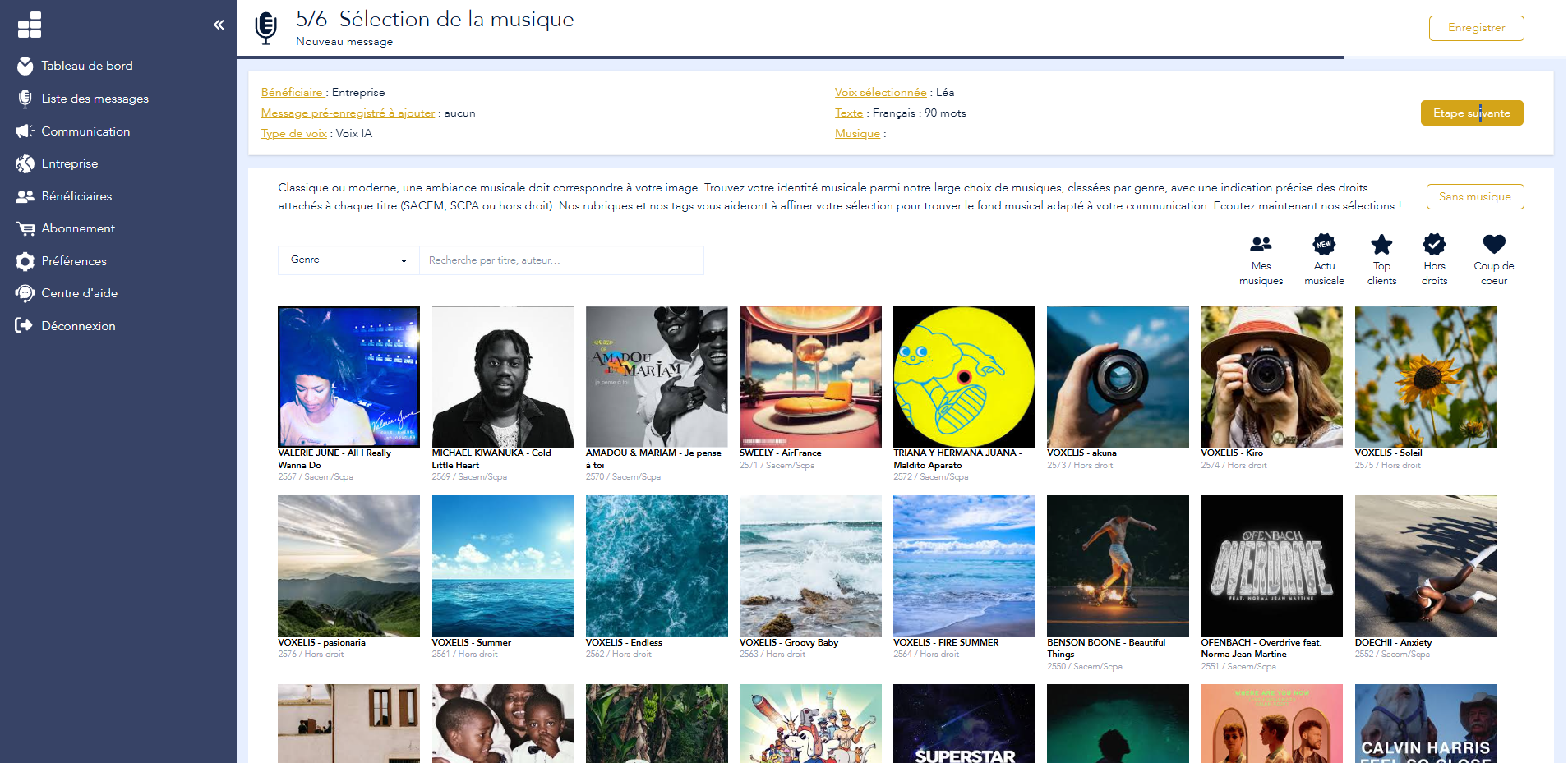
Tippen oder fügen Sie Ihre Nachricht in Voconix ein. Vorgefertigte Vorlagen sind für jede Situation verfügbar: Empfang, Anrufbeantworter, IVR, Warten, Schließung, Urlaub.
25 KI- und menschliche Stimmen in 5 Sprachen. Fügen Sie optional Musik aus über 10.000 lizenzfreien Titeln hinzu. Automatisches Mischen inklusive.
MP3- oder WAV-Datei, die mit Ihrer Telefonanlage kompatibel ist, oder automatische Benachrichtigung von Ihrem Telekom-Installateur. Keine zusätzliche Konvertierung.
Versuchen Sie es jetzt. Der Player oben auf dieser Seite ist das echte Voconix-Tool. Geben Sie Ihren Text ein, wählen Sie eine Stimme und hören Sie sich das Ergebnis an.
Erstellen Sie Ihre erste Nachricht kostenlos Siehe Preise10. Beispiele für gebrauchsfertige Text-to-Speech-Sprachmitteilungen
Diese Vorlagen können direkt in Voconix verwendet werden. Kopieren Sie sie, fügen Sie sie in den Player ein, wählen Sie eine Stimme und hören Sie sie in 10 Sekunden an.
«Hallo, Sie sind mit [Name des Unternehmens] verbunden. Unsere Berater sind von Montag bis Freitag von 9 bis 18 Uhr erreichbar. Wenn Sie eine Anfrage haben, schreiben Sie uns bitte an contact@[domaine].fr. Bis bald.»
Diese Nachricht erstellen →.«Hallo, dies ist die Mailbox von [Vorname Nachname]. Ich bin derzeit nicht erreichbar. Bitte hinterlassen Sie Ihren Namen, Ihre Nummer und den Zweck Ihres Anrufs, ich rufe Sie so bald wie möglich zurück.»
Diese Nachricht erstellen →.« Vielen Dank für Ihren Anruf. Alle unsere Berater sind derzeit online. Ihr Anruf ist für uns sehr wichtig. Wir werden Ihnen in Kürze antworten».»
Diese Nachricht erstellen →.«Willkommen bei [Unternehmen]. Für die kaufmännische Abteilung tippen Sie 1. Für die technische Abteilung tippen Sie 2. Für die Buchhaltung tippen Sie 3. Um mit einem Berater zu sprechen, tippen Sie 0.»
Diese Nachricht erstellen →.«Guten Tag, aufgrund einer außerordentlichen Schließung an diesem Tag sind unsere Büros geschlossen. Wir sind am [Datum] um [Uhrzeit] wieder für Sie da. Sie können uns unter contact@[domain].de schreiben.»
Diese Nachricht erstellen →.«Guten Tag und vielen Dank für Ihren Anruf bei [Unternehmen]. Ihr Anruf wird in Kürze entgegengenommen. Ein Berater wird sich in Kürze bei Ihnen melden».»
Diese Nachricht erstellen →.«Hallo, das Team [Firma] ist von [Datum] bis [Datum] im Urlaub. Wir sind am [Datum] wieder da und werden Ihre Nachrichten nach unserer Rückkehr bearbeiten.»
Diese Nachricht erstellen →.«Hallo, Sie sind bei [Firma] / Hello, you've reached [Company]. Für Französisch tippen Sie 1 / For English, press 2.»
Diese Nachricht erstellen →.Diese Vorlagen dienen als Ausgangspunkt. Voconix bietet vorgefertigte Skripte für jede Situation direkt im Tool an.
Erstellen Sie Ihre erste Nachricht kostenlos Siehe Preise